
This is a guest article by Cox Trevor. Trevor is a Professor of Acoustic Engineering at the University of Salford, he explore the workings of the voice and how it can be adapted to different styles If you would like to hear more. Book your tickets to his next talk with this link.
Voice control: why AI must resist our bad habit of stereotyping human speech

Shutterstock
Trevor Cox, University of Salford
Voice control gadgets – such as Amazon’s Alexa, Google’s Home or Apple’s Homepod – are becoming increasingly popular, but people should pause for thought about advances in machine learning that could lead to applications understanding different emotions in speech.
The CEO of Google, Sundar Pichai, recently said that 20% of the company’s searches are initiated by voice via mobile phones. And, at the end of 2017, analysis of the US market suggested that a total of 44m Amazon Alexa and Google Home devices had been sold.
The technology has increasingly impressive abilities to recognise words, but – as an expert on acoustics – it is clear to me that verbal communication is far more complex. How things are said can be just as important as the words themselves. When someone says “I’m alright”, the tone of their voice might tell you their mood is the opposite to what they claim.
Voice control gadgets, also known as smart speakers or virtual assistants, can be frustrating to use because they only pay attention to the words, and mostly ignore how speech is expressed. Tech giants hope that the next frontier for devices, such as Amazon Echo, will be to detect how a person is feeling from their voice to make interactions more natural.
Read more:
Tech firms want to detect your emotions and expressions, but people don’t like it
The human voice can give away information about who that person is, where they come from and how they are feeling. When a stranger talks, people immediately pick up on their accent and intonation and make assumptions about their class, background and education.
If voice control gadgets pick up on such information, speech interfaces could be improved. But it’s worth remaining wary of unintended consequences. The technology relies on machine learning – a branch of artificial intelligence that brings together algorithms and statistics learnt by a machine that has been fed reams of data – and so its behaviour is not entirely predictable.
Is the future smart or dumb?
Research shows that speech examples used to train the machine learning application is likely to lead to bias. Such problems with the technology have been evident in popular tools such as Google Translate.
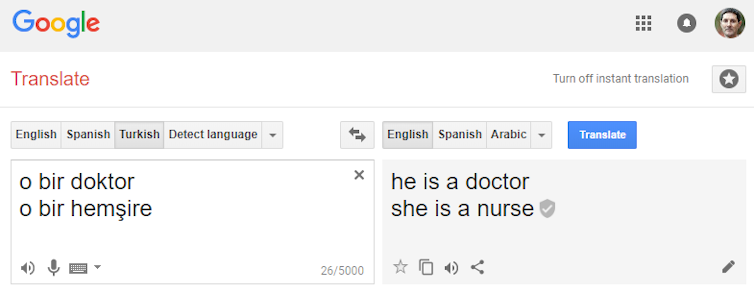
When used, for example, to translate the Turkish phrases “o bir doktor” and “o bir hemşire” into English, Google’s service returns the results “he is a doctor” and “she is a nurse”. But “o” is a gender-neutral third-person pronoun in Turkish. The presumption that a doctor is male and a nurse is female reflects cultural prejudices and the skewed distribution of gender in the medical profession.
Google Translate picked up a human cultural bias that was in the data the algorithms were trained on and the end result is a sexist translation system.
Screengrab
It is not an easy task to solve such problems because machine learning echoes human stereotypes. When humans listen to voices, they simplify the job of working out how to respond to someone by using rules of thumb.
Research shows that when people hear a woman ending lots of her sentences with an upward inflexion, known as uptalk, the typical assumption is that they are young. If a man speaks with a deep voice, there’s an assumption that he is big and strong. Such simplified assumptions about speech can lead to prejudiced judgements.
Criminal suspects with a Birmingham accent, one study found, were more likely to be rated as guilty compared to those with a more neutral accent. Research has also revealed that a non-native accent was perceived to be more untruthful.
Working out whether a person is angry, happy or sad from their speech could be really useful for anyone who uses voice control devices. But the vocal cues people emit vary from person to person, and across languages and cultures. Humans don’t always recognise emotions correctly, as anyone who has ever been in a relationship will testify, so why should it be expected that machines can do a better job?
Research into people’s aural “gaydar” – a colloquial term used by some who claim they can intuitively tell if someone is gay, lesbian or bisexual – offers a good example of ambiguous and even bogus signals. Listeners make assumptions, for example, about how a gay male should sound, such as having a higher pitched voice, but these are often wrong. Actors playing up to incorrect stereotypes in apparent responses to audience expectations became something of a cultural norm on TV screens, research shows.
Read more:
DeepMind: can we ever trust a machine to diagnose cancer?
The individualised, natural ambiguity of vocal signals is likely to lead to mistakes unless technology companies learn from their mishaps. Ingrained prejudices could be learned by applications that attempt to interpret human voices, given that the technology relies so heavily on learning from the data it is fed.
![]() Technology firms developing voice control devices and services may already talk to acoustic experts. But they need to listen closely to the warnings to better understand the pitfalls to avoid, before applying machine learning to decoding the human voice.
Technology firms developing voice control devices and services may already talk to acoustic experts. But they need to listen closely to the warnings to better understand the pitfalls to avoid, before applying machine learning to decoding the human voice.
Trevor Cox, Professor of Acoustic Engineering, University of Salford
This article was originally published on The Conversation. Read the original article.
If you would like to hear more from Cox Trevor, you can book your tickets to his next talk with this link.